 百万个冷知识
百万个冷知识前段时间facebookChavanges了一则讲搜寻各方面的该文,真的蔬果还较为多,尽管我没太做过搜寻各方面,但有关控制技术基本上却是相连的,上面是学术论文的主要就文本
简述
embedding-based retrieval(EBR)在产业界早已许多年了,但facebook搜寻始终却是延用的Boolean matching model。这篇该文主要就如是说了怎样将EBR布署到facebook搜寻控制系统中去,主要就强化的文本主要包括modeling/serving和full-stack optimization三部份,具体文本文本如下表右图图右图
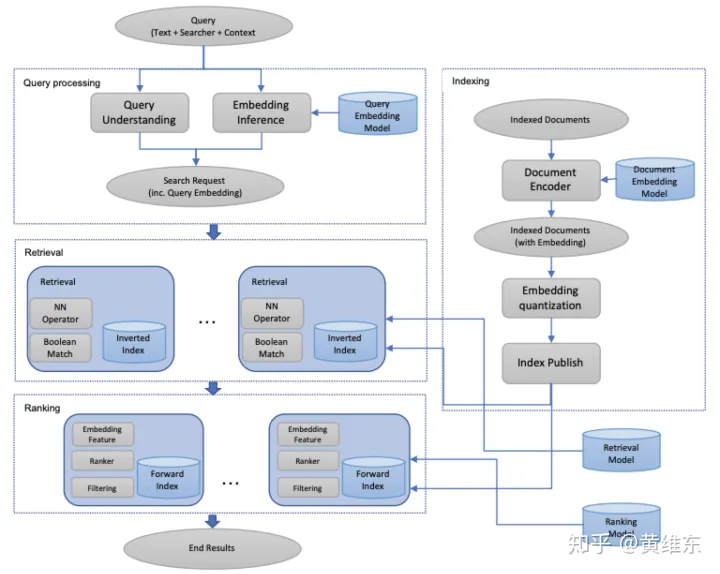
Methodology
Evaluation Metrics最终目标子集T={t1,t2,...tN}, 搜寻回到子集top K,{d1, d2, ...dK},具体文本计算方法如下表右图recall@K=∑i=1Kdi∈TNrecall@K = \frac{\sum_{i=1}^K{d_i \in T}}{N}
Loss Function对两个 是两个和有关联的是差值triplet(q(i),d+(i),d−(i)),q(i)是两个query,d+(i)和d−(i)有关联的是差值documentstriplet(q^{(i)},d_+^{(i)},d_-^{(i)}),q^{(i)}是两个query,d_+^{(i)}和d_-^{(i)}有关联的是差值documents
具体文本式子如下表右图右图

其中D(u, v)是两个距离度量式子,对向量u和v,m表示在差值样本之间有两个最小距离约束,在实际应用中m对效果影响很大,会对recall指标有5%到10%的影响
Unified Embedding Model主要就如是说上面部份的D(u,v)的计算,u和v其实就是双塔模型出来的两个向量,然后通过cosine去度量距离,其中双塔的输入并不仅仅是query和document,query这一侧塔的输入还会主要包括location和社交连接有关信息,而document则还会主要包括聚集的local和社交簇信息,具体文本网络结构如下表右图右图

训练数据构造这一块主要就就是做一些对比实验看怎样选择差值样本
正样本点击,拿没有点击的结果做为负样本 vs 全局随机sample document,前者模型的召回明显差,这里也可以理解,拿没有点击的结果做负样本相比全局sample其实对任务定义来说会难很多点击做为正样本 vs 所有展现的做为正样本 vs 拿展现+点击加权做为正样本 这三者效果基本上差不多这块最终结论是建议选用点击做为正样本,随机sample做为负样本
Feature engineering使用统一的embedding model也就是上面的网络结构,相比直接拿text做embedding有不少优点,主要就就是方便加一些其他特征进去,这个很容易理解,尤其在一些特定场景上,比如说events搜寻(+18%)和group搜寻(+16%),这里主要就是因为加了location和social的特征进去,明显对这两个场景会很有帮助
上面是一些特征工程具体文本细节
针对text features,Character n-gram相比word n-grams,不仅仅体现在embedding的table size会小,同时训练起来会更快速,然后后者还会有out-of-vocabulary的问题,但最后发现使用character trigrams + word n-grams效果最好(+1.5% recall gain),这里面还提了下用embedding比boolean term matching的优点,也很简单就是增加了泛化性,能够匹配一些模糊词语和一些缩写词针对location features同时在query和document侧都加入了,在query侧会抽取出搜寻者的city,region,country和语言特征,document侧会加入一些公共信息,比如说团体的位置,具体文本提升见下表针对social embedding features,单独针对user和entities的social graph训练了两个embedding model加到模型中,具体文本提升见下表
线上布署的是两个倒排索引基于ANN(approximate near neighbor)搜寻的,优点主要包括存储空间开销小,同时较为容易整合到现有搜寻控制系统中,整个控制系统主要包括二部份
coarse quantization,将embedding向量量化到coarse cluster里,一般是通过K-means算法,该文对比了IMI和IVF算法,IMI算法要好一些product quantization,主要就是提供高效的向量距离计算方法,该文对比了PQ、OPQ和PQ加上PCA转换三种方法,效果如下表右图图右图
接着该文如是说了针对ANN的超参数怎样调节的方法和经验
coarse quantization主在做的过程中发现尤其IMI算法有一半的clusters只有很少的样本量,因此使用扫描的documents数量来帮助调参,效果会好很多当线上线下效果差别较为大的时候需要去调ANN里面的超参OPQ这个算法较为好要记得尝试pb_bytes设成d/4是两个很好的经验值nprob,numclusters和pq_bytes需要测试多组来了解线上真正性能,这样好去根据预算来决定模型尺寸上限,以免线下调研搜寻很多不能上线的超参数后面还有一些将控制系统实现的文本就不如是说了
Later-Stage Optimizationembedding based 方法做retrieval的结果一般会传给后面的排序layer做为输入,但在实际线上会出现一些新的结果使得可能后面的layer并不能很好识别出好的结果来,针对这样的问题有两种解决方法
把embedding similarities做为特征传到后面模型去学习,不仅仅能够帮助后面模型更好去做识别,同时能够提供一些语义相似的信息传到后面,具体文本similarities尝试过cosine,hadamard product,raw embeddings,从实验结果来看cosine的效果是最好的embedding-based 方法做retrieval 能够帮助提高recall但精度上相比term matching效果可能会差一点,为了提高精度,可以加入两个反馈回路让人工实时把结果去打分,再把人工打分结果重训模型,这样做可以帮助提高recall的精度Hard Mininghard negative mining
该文首先说发现实际模型排序的时候只能把相似的放到前面但无法把最好的放在第一,有可能是训练任务太简单了,因此可以选取向量空间里面和positive样本里向量相似的document做为负样本对在实际online场景里,在两个batch内主要包括n个positive pair(q,d),然后再从两个document池子里和q计算similarity,选两个similarity最大的做为negative样本对,实验发现这种方法效果显著,对people search提升8.38%召回,对events search提升5.33%召回,对groups search提升7%召回,并且最好的配置是两个hard negative配1个positive但上述方法有个问题就是难以产生足够的hard negatives,因此该文又提供了一种offline hard negative mining的方法,首先针对每个query产生top k个result,然后选择最难的两个negative,再重新训练模型接着该文对比了上述选择negative sample的方法,发现仅仅使用hard negative方法是很难比随机选取negative方法效果好,因此又尝试了两种策略来选择,(1) 慢慢提高easy negative/hard negative的比例直到100:1为止(2)使用transfer learning从hard negative学习出来的模型到easy negative的模型,并且试了下easy到hard这个方向效果不好最后该文讲述了下线上生成negative这种方法其实是开销很大的,因此同样可以使用ANN的方法去查找top k个result,并且对random sample会比hard negative效率高很多,因此线上只会部份使用hard negative在训练中hard positive mining
从搜寻的日志中去挖掘失败的search session,再为这些query找潜在的documents组成正样本对放到模型中学习可以帮助模型训练(只能说明facebook是真牛逼,各种找人工去做一些高质量样本来帮助模型学习)
Embedding Ensemble这里首先讲了下设计思想,出发点主要就是考虑到在挑选训练数据的时候,分为hard和easy两种类型的选择方式,hard选择能够提升模型的精度,easy选择也很重要能够表达模型的搜寻空间,在实际实验中也发现easy这种选择方式是主要就为了召回K强化的,但如果K很小的时候就会发现精度较差,hard方式则是可以在两个较为小子集去做排序使用,但用来召回效果较差,因此参考我们在控制系统经常使用召回+排序多阶段方法去完成任务一样,我们可以考虑去ensemble多种不同hardness level的模型,上面接着讲了两种ensemble的方式
Weighted Concatenation,其实很简单就是根据不同embedding model进行bagging,在测试集的表现进行赋值,多个embedding计算的相似度的式子为 Sw(Q,D)=∑i=1naicos(VQ,i,UD,i),cos(EQ,ED)=Sw(Q,D)∑i=1nai2nS_w(Q,D)=\sum^n_{i=1}a_icos(V_{Q,i},U_{D,i}),cos(E_Q,E_D)=\frac{S_w(Q,D)}{\sqrt{\sum^n_{i=1}a^2_i}\sqrt{n}}Cascade Model,分两阶段,这一块先是用easy方式然后输出接hard方式,但该文说这种方式效果不如weighted concatenation,后面改进了一下先是通过text embedding去进行选择然后再通过unified embedding model去做最终召回,效果上也是会有提升
.jpg)
.jpg)
.jpg)

.jpg)

.jpg)
.jpg)
.jpg)


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
